«Ручной» парсинг сайтов TextPipe Pro + Teleport Pro + Open Office

Один из самых сложных процессов при организации и работе интернет магазина является наполнение его товарами. Особенно, это касается магазинов с большим количеством позиций номенклатуры (1000 и более). Ручное введение такого количества номенклатуры может обойтись достаточно дорого. На помощь приходят сайты «конкурентов», продающих те же товары (возможно, того-же поставщика). «Скачав» информацию с их сайтов на свой можно значительно расширить номенклатуру. Но неужели придется нанимать программистов для написания «парсера» под каждый такой сайт?
В этой статье речь пойдет о том, как без помощи программистов «парсить» любой сайт с необходимой информацией, и представить результаты работы в удобной таблице для ручного редактирования или импорта в CMS, 1С или другие системы.
Часто парсинг сайтов так же необходим для того, что бы собрать e-mail адреса потенциальных клиентов или партнеров для целевой рассылки. Найдя интернет справочник копманий вашей сферы бизнеса (коих сейчас очень много), вы можете самостоятельно «извлечь» e-mail адреса потенциальных партнеров и разослать им прсьма с предложениями.
От сложности «парсинга» весь процесс занимает от десяти минут до 2-3 часов. На выходе — вся необходимая информация в удобной табличной форме. Итак, приступим.
Что можно парсить
В общем-то извлекать с сайтов можно любую однотипную информацию, или данные находящиеся в в каком либо определенном блоке страницы. Легче всего собрать с сайтов оставленные e-маил адреса. Так же можно парсить телефоны, названия, описания, картинки и цены товаров. Гораздо сложнее, но можно утянуть с интернет-магазина и все товарные свойства. Парсить можно любые сайты, написанные на HTML, PHP, Python и других языках, и использующие любые CMS платформы, в том числе и WordPress, Drupal, Joomla, 1С-Битрикс и т.д.
Возможность сложного парсинга с использованием «составных фильтров» дает применение шаблонов отображения, как основного принципа программирования. Таким образом, например, все карточки товаров в интернет-магазине, по сути, имеют одинаковую структуру, отличается только представленная информация: картинка, цена, свойства, описание. Таким образом составив «фильтр» для одной страницы сайта, можно его применить ко всем страницам с этим шаблоном.
(В связи с «шаблонностью» страниц так же возникает возможность сравнения 2х страниц с одним и тем же шаблоном и удаления всех повторяющихся элементов. Таким образом оставшиеся элементы и будут нужным нам контентом. Однако, описание этой возможности не входит в тематику данной статьи.)
В общем парсить можно практически любую информацию. Понимание, что легче, а что сложнее приходит с опытом. В этой статье мы разберем основной «алгоритм» действий. Систему в каждом конкретном случае вам придется чаще всего разрабатывать самим.
Скачаем сайт
Все действия над данными мы будем проводить на локальной машине, поэтому для работы нам следует скачать весь парсируемый сайт (к счастью нам не потребуется скачивать все картинки/видео и другой контент, нас интересуют только HTML, PHP и другие кодовые страницы). Для скачивания сайта из интернета существует несколько хороших решений. Самое популярое из них — программа Teleport Pro.
Создаем новый проект. «Копировать сайт на диск для просмотра», вводим адрес сайта и глубину исследования, выбираем пункт «Just Text» (Только текст), сохраняем и запускаем проект.

Определение нужных страниц
Если нам необходима информация с определенных страниц сайта, например, с карточек товаров, желательно удалить остальнык страницы до начала обработки (что бы не мешались, и небыло «грязи» в резуультатах). Чаще всего нужные нам страницы можно определить пш имени скаченного файла, например, по присутствию определенной последовательности символов. Если возможно это сделать, желательно удалить остальные файлы по маске (например используя Total Commander), оставив только нужные нам страницы.
Составляем «фильтр»
Теперь, все, что нам нужно, выделить из сохраненных файлов нужный форагмент кода. Делается это с помощью мощной программы — массового обработчика текстовых файлов Text Pipe.

Пример 1. Извлечение e-mail адресов
Самая простая задача — извлечение с сайта e-mail адресов. После того, как нужный нам сайт скачен и открыт проект TextPipe, на нужно настроить выборку e-mail адресов и сохранение результата в нужный файл. Для этого:
- В левой панели со списком функций TextPipe выбираем в разделе «Извлечь» пункт «Извлечь адреса эл. почты» и перетаскиваем его на место строки «Click >>Here<<» в списке фильтра левее;
- Щелкаем на пункт «Файл вывода» в списке фильтра для настройки формата сохранения результата. Выбираем пункт «В один файл вывода» и указываем путь к файлу, в котором будем сохранять результат (файл должен иметь расширение .txt);
- Во вкладке «Файлов в обработке» удаляем все ненужное в списке и выбираем папку со скаченным сайтом;
- Нажимаем кнопку «Делать (реально)» для запуска фильтрации.
После окончания операции в файле, который был задан в качестве результирующего будут записаны все найденные на сайте e-mail адреса.
Пример 2. Извлечение номеров телефонов
К примеру, вам необходимо сделать sms рассылку по людям с определенными интересами. например «Авто» или «Детские вещи». Для составления такой базы телефонных номеров достаточно найти тематическую доску объявлений, форум или местный портал, где посетители оставляют свои номера телефонов (чаще всего это делают при продаже б/у вещей). После этого, извлекая телефонные номера с таких сайтов мы сформируем собственную базу потенциальных клиентов для рассылки.
Однако, стоит учесть, что извлечение e-mail адресов с сайта становится более простой задачей, т.к. разработчики программы TextPipe заранее позаботились о составлении фильтра, включив в программу функцию извлечения адресов электронной почты. К сожалению, такая предустановка есть не для всякого рода задач. Часто необходимо составлять разные по сложности фильтры вручную. Например, для извлечения номеров телефонов с сайта.
Для решения этой задачи в программе TextPipe имеется функция «Извлечь соответствия», которая по шаблону (Perl) способна извлечь из текстовых файлов все данные соответствующие этому формату.
Удалите функцию «Извлечь адреса эл. почты» (если вы редактируете предыдущий пример) и на ее место перетащите функцию «Извлечь соответствия» из того же раздела. В поле Pattern tupe настроек функции выберите Pattern Perl. Теперь, в строку «Извлечь соответствия» необходимо вставить регулярное выражение на языке Perl. При этом, необходимо учесть, что если пользователи сайта забивают телефон не по определенному шаблону, формат представления телефонных номеров на сайте может сильно отличаться начиная от +71231234567 и заканчивая 8-123-123-45-45 с различными вариациями. Часто под каждый сайт необходимо подбирать собственный шаблон. Итак, шаблон для извлечения номера телефона, выглядит примерно следующим образом:
((8|\+7|)(\d{10}|(.|)(\d{3}).(\d{3,})(.|)(\d{2,})(.|)(\d{2,}))).
Теперь, перед тем, как мы запустим процесс извлечения на всем скаченном сайте, нам необходимо проверить шаблон на работоспособность. В TextPipe это делается во вкладке «Зона учебного прогона». В левую часть окна во вкладке вставляется html код страницы с сайта (которая должна содержать номер телефона). После этого нажимаем кнопку «Учебный прогон», и в правом окне видим результат работы фильтра только на заданном коде. Таким образом мы можем оттачивать работу нашего фильтра. После того, как фильтр на данном коде работает правильно, не поленитесь проверить его работу на 2-3 других файлах, где данные (номер телефона) представлены в разном формате, что бы фильтр работал на всех форматах номеров телефонов представленных на сайте (или хотя бы на большинстве). После этого запускаем работу программы («Делать (реально)»).
Пример 3. «Составной фильтр». Извлечение описания товаров
Иногда требуемые данные нельзя подогнать под определенный формат и написать к нему фильтр (как в примере 2). Для таких данных приходится выстраивать многоуровневые «составные» фильтры, применяя сначала одни функции TextPipe, а затем другие. На практике бывают цепочки более чем из 10 функций. Но помните, чем сложнее составной фильтр, тем меньше вероятность, что он будет правильно работать на всех файлах сайта (ввиду того. что при тесте сложные фильтры адаптируются под один код, а работают на различных вариантах этого кода на всем скопированном сайте).
- Проверяем, не находится ли описание товара на одной и той же строке html кода во всех файлах? Иногда это случается, поэтому парсинг таких данных превращается в сплошное удовольствие, т.к. для этого есть фильтр «Удалить диапазон строк» («Удалить» -> «Удалить строки»). Применив его 2 раза (например, с 1 по 99 строку и с 2 по 1000, если нужная нам строка 100я), мы сформируем список нужных нам описаний товаров.
- Проверяем, можно ли выделить уникальную строку с постоянным элементом, в который представлен нужный нам контент. Например, если все описание товара находится в одной строке, и помещено в блок <div id=»text»></div>, мы можем оставить только нужный нам блок в документе с помощью функции «Удалить не согласующиеся строки» («Удалить» -> «Удалить строки»).
Обрамление <div id=»text»></div> и другой html код (при необходимости) можно заменить с помощью функции «Remove all tags» («Удалить» -> «HTML and XML») или функции «Найти точно» (группа «Поиск и замена»).
- Если мы имеем дело с многострочным контентом (например, когда нам требуется парсить длинные описания товаров). Проверяем, есть ли уникальные теги, или их комбинаци, окружающие нужный нам контент. Например, если нужный нам тест заключен в блок <div id=»text»></div>, задача сводится к тому, что бы удалить весь контент кроме этого блока. Это можно сделать с помощью функции «Найти схему (Perl Style)» (группа «Поиск и замена»). И с помощью регулярного выражения «.*» (обозначающая лубую последовательность символов). Например:
«.*<div id=»text»>»:
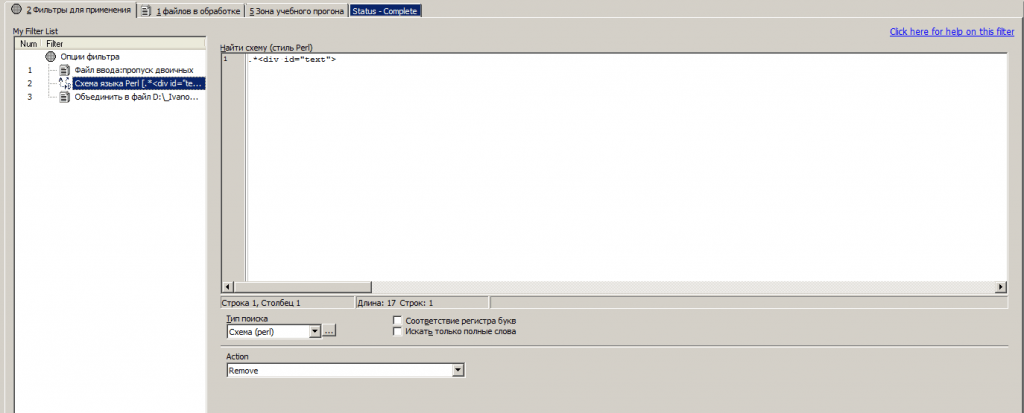 Конструкция удаляет все знаки стоящие перед первым попаданием «<div id=»text»>», включительно. Аналогично можно удалить лишний текст после необходимой надписи.
Конструкция удаляет все знаки стоящие перед первым попаданием «<div id=»text»>», включительно. Аналогично можно удалить лишний текст после необходимой надписи.
После этого не забудьте преобразовать полученный текст в одну строку (удалить символы переноса строки «\n», «\r»), для того, что бы описания из различных файлов после обработки TextPipe не слились в одно.

Но зачем нам нужны просто описания товаров, без привязки к артикулу или названию?
Резонный вопрос.Поэтому, после извлечения описаний товаров (или перед) мы сохраним результирующий файл и таким же образом извлечем артикулы или названия товаров (или и то и другое), после чего вставим все эти данные в табличку MS Excel (Open Office Calc) по колонкам. В 99% случаев, если все сделано правильно очередность следования артикулов-названий-описаний сохраняется, таким образом можно не опасаться, что привязка собьется. Однако, на всякий случай рекомендую проверить на 2-3 товарах из разных частей полученного списка.
Составной фильтр в табличном формте .csv
Иногда, по некоторым причинам, при совмещении списка артикул-название-описание приводит к смещению привязки, и названия товаров в таблице не соответствуют описанию. Если ничего сделать не удается, необходимо настраивать еще более сложный фильтр для сбора такой таблицы в 1 прогон. Сделать это нам поможет формат таблиц .csv. В стандартном варианте формата .csv строки считаются строками таблицы, а разделителем столбцов считается символ » ; » (точка с запятой):
строка1ячейка1;строка1ячейка2;строка1ячейка3
строка2ячейка1;строка2ячейка2;строка2ячейка3
строка3ячейка1;строка3ячейка2;строка3ячейка3
Если сохранить файл с таким текстом и установить ему расширение .csv, он откроется в виде таблицы.
Но со стандартным форматом часто возникают проблемы, потому, что в описаниях товаров, артикулах или других нужных нам элементах может часто применяться знак » ; «, из-за чего нужные колонки в .csv файле могут быть разделены неправильно. Что бы решить эту проблему, мы можем заменить знак » ; » на любой редкоиспользуемый символ. Я чаще всего использую символ » ~ «, некоторым больше нравится буква » ё «. Тогда наш пример примет вид:
строка1ячейка~строка1ячейка2~строка1ячейка3
строка2ячейка1~строка2ячейка2~строка2ячейка3
строка3ячейка1~строка3ячейка2~строка3ячейка3
Так же сохранив этот файл с расширением .csv и открыв с помощью MS Excel мы не получим ожидаемого результат. Но табличный редактор Open Office Calc позволяет нам задать символ разделения столбца вручную. И, при необходимости, кодировку файла.

Таким образом, задача по формированию табличного представления данных, полученных из TexPipe сводится к тому, что созданный фильтр должен выдавать нужные данные в одну строку с разделителем «~» между ними. Составив такой фильтр мы неизбежно сохраним привязку артикул-название-описание.
Хотя, создание и тестирование такого фильтра требует гораздо больше времени, метод иногда просто незаменим для парсинга интернет-магазинов.
Поделиться "«Ручной» парсинг сайтов TextPipe Pro + Teleport Pro + Open Office"


